When To Use RAG Eval Template
This Eval evaluates whether a retrieved chunk contains an answer to the query. It’s extremely useful for evaluating retrieval systems.RAG Eval Template
We are continually iterating our templates, view the most up-to-date template on GitHub.
How To Run the RAG Relevance Eval
Benchmark Results
This benchmark was obtained using notebook below. It was run using the WikiQA dataset as a ground truth dataset. Each example in the dataset was evaluating using theRAG_RELEVANCY_PROMPT_TEMPLATE above, then the resulting labels were compared against the ground truth label in the WikiQA dataset to generate the confusion matrices below.

Try it out!
GPT-4 Result
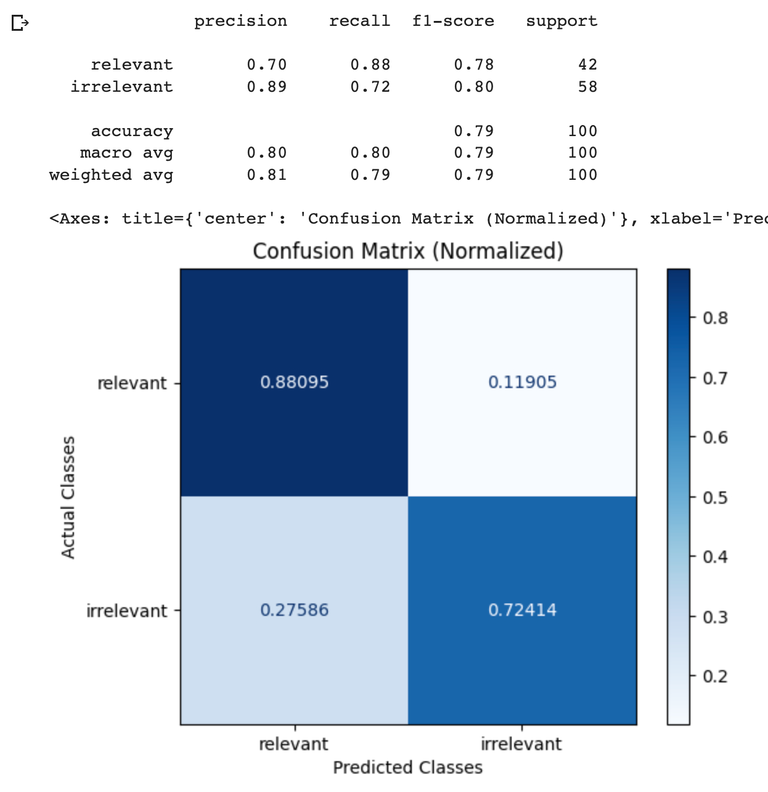
Scikit GPT-4
| RAG Eval | GPT-4o | GPT-4 |
|---|---|---|
| Precision | 0.60 | 0.70 |
| Recall | 0.77 | 0.88 |
| F1 | 0.67 | 0.78 |
| Throughput | GPT-4 |
|---|---|
| 100 Samples | 113 Sec |