
Google Colab
colab.research.google.com
Example Human vs AI on Arize Docs:
Question: What Evals are supported for LLMs on generative models? Human: Arize supports a suite of Evals available from the Phoenix Evals library, they include both pre-tested Evals and the ability to configure cusotm Evals. Some of the pre-tested LLM Evals are listed below: Retrieval Relevance, Question and Answer, Toxicity, Human Groundtruth vs AI, Citation Reference Link Relevancy, Code Readability, Code Execution, Hallucination Detection and Summarizaiton AI: Arize supports LLM Evals. Eval: Incorrect Explanation of Eval: The AI answer is very brief and lacks the specific details that are present in the human ground truth answer. While the AI answer is not incorrect in stating that Arize supports LLM Evals, it fails to mention the specific types of Evals that are supported, such as Retrieval Relevance, Question and Answer, Toxicity, Human Groundtruth vs AI, Citation Reference Link Relevancy, Code Readability, Hallucination Detection, and Summarization. Therefore, the AI answer does not fully capture the substance of the human answer. Overview of template:We are continually iterating our templates, view the most up-to-date template on GitHub.
How to run the Human vs AI Eval:
Benchmark Results:
The follow benchmarking data was gathered by comparing various model results to ground truth data. The ground truth data used was a handcrafted dataset consisting of questions about the Arize platform. That dataset is availabe here. GPT-4 Results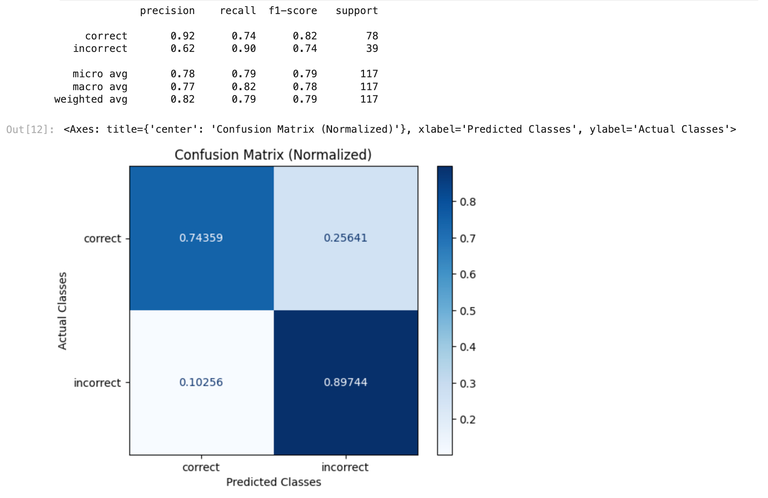
| Eval | GPT-4o | GPT-4 |
|---|---|---|
| Precision | 0.90 | 0.92 |
| Recall | 0.56 | 0.74 |
| F1 | 0.69 | 0.82 |