When To Use Q&A Eval Template
This Eval evaluates whether a question was correctly answered by the system based on the retrieved data. In contrast to retrieval Evals that are checks on chunks of data returned, this check is a system level check of a correct Q&A.- question: This is the question the Q&A system is running against
- sampled_answer: This is the answer from the Q&A system.
- context: This is the context to be used to answer the question, and is what Q&A Eval must use to check the correct answer
Q&A Eval Template
We are continually iterating our templates, view the most up-to-date template on GitHub.
How To Run the Q&A Eval
Benchmark Results
The benchmarking dataset used was created based on:- Squad 2: The 2.0 version of the large-scale dataset Stanford Question Answering Dataset (SQuAD 2.0) allows researchers to design AI models for reading comprehension tasks under challenging constraints. https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/reports/default/15785042.pdf
- Supplemental Data to Squad 2: In order to check the case of detecting incorrect answers, we created wrong answers based on the context data. The wrong answers are intermixed with right answers.
QA_PROMPT_TEMPLATE above, then the resulting labels were compared against the ground truth in the benchmarking dataset.

Try it out!
GPT-4 Results
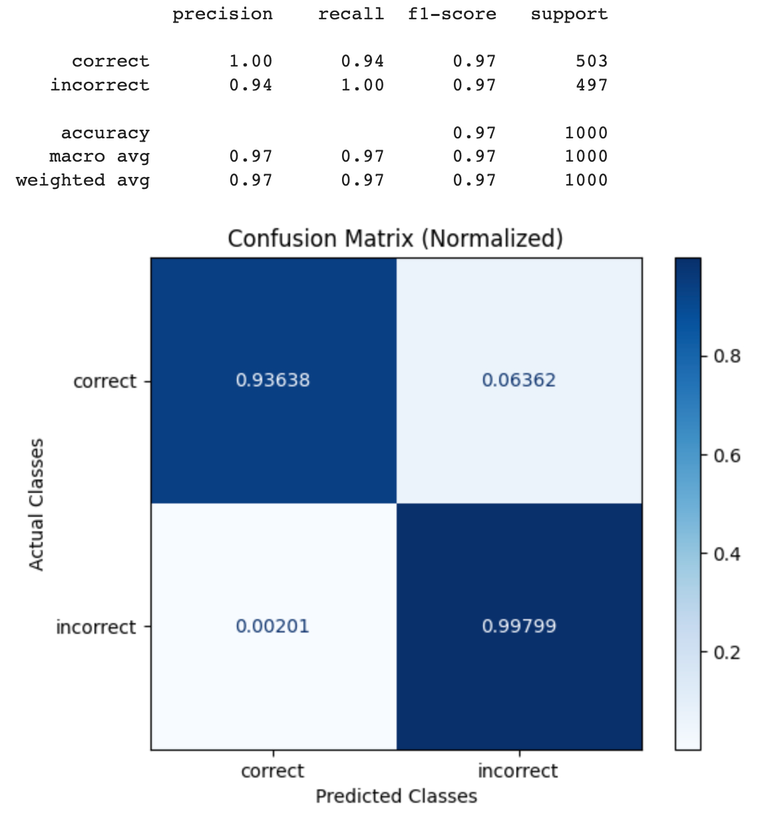
| Q&A Eval | GPT-4o | GPT-4 |
|---|---|---|
| Precision | 1 | 1 |
| Recall | 0.89 | 0.92 |
| F1 | 0.94 | 0.96 |
| Throughput | GPT-4 |
|---|---|
| 100 Samples | 124 Sec |