| Framework | Example notebook |
|---|---|
| Open AI Functions |   |
Overview
Data extraction tasks using LLMs, such as scraping text from documents or pulling key information from paragraphs, are on the rise. Using an LLM for this task makes sense - LLMs are great at inherently capturing the structure of language, so extracting that structure from text using LLM prompting is a low cost, high scale method to pull out relevant data from unstructured text.Structured Extraction at a GlanceLLM Input: Unstructured text + schema + system messageLLM Output: Response based on provided text + schemaEvaluation Metrics:
- Did the LLM extract the text correctly? (correctness)
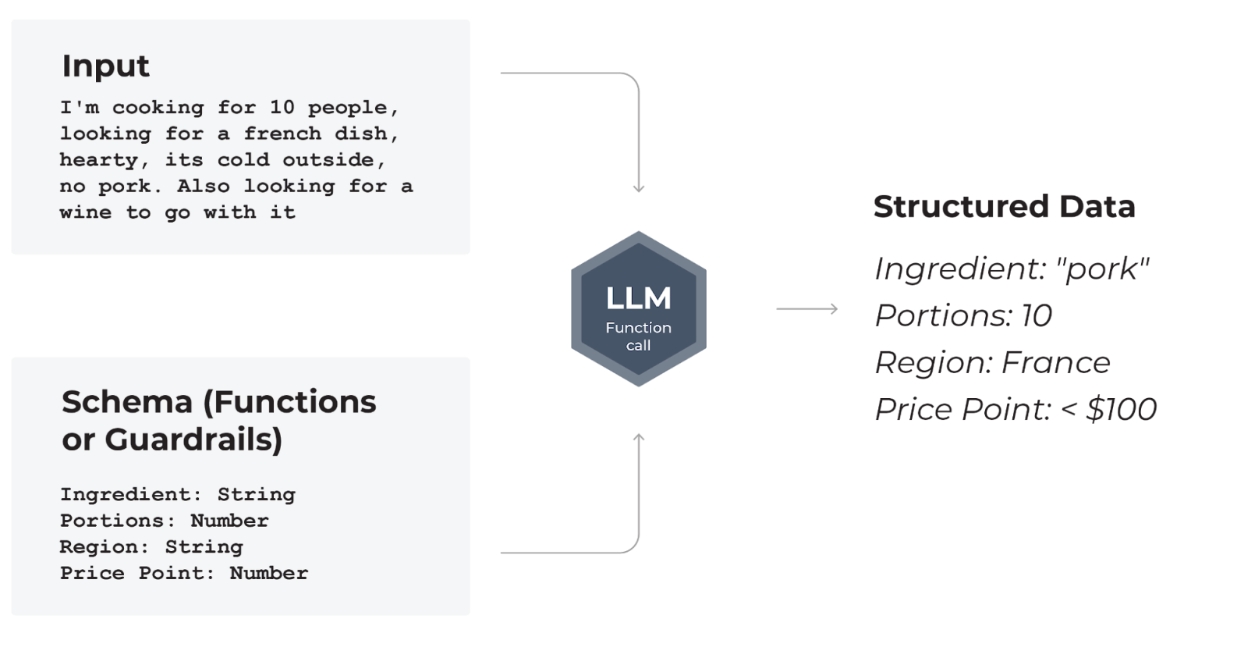
User: I need a budget-friendly hotel in San Francisco close to the Golden Gate Bridge for a family vacation. What do you recommend?As the application designer, the schema you may care about here for downstream usage could be a flattened representation looking something like:
Implementing a structured extraction application
Structured extraction is a place where it’s simplest to work directly with the OpenAI function calling API. Open AI functions for structured data extraction recommends providing the following JSON schema object in the form ofparameters_schema(the desired fields for structured data output).
ChatCompletion call to Open AI would look like
Inspecting structured extraction with Phoenix
You can use phoenix spans and traces to inspect the invocation parameters of the function to- verify the inputs to the model in form of the the user message
- verify your request to Open AI
- verify the corresponding generated outputs from the model match what’s expected from the schema and are correct
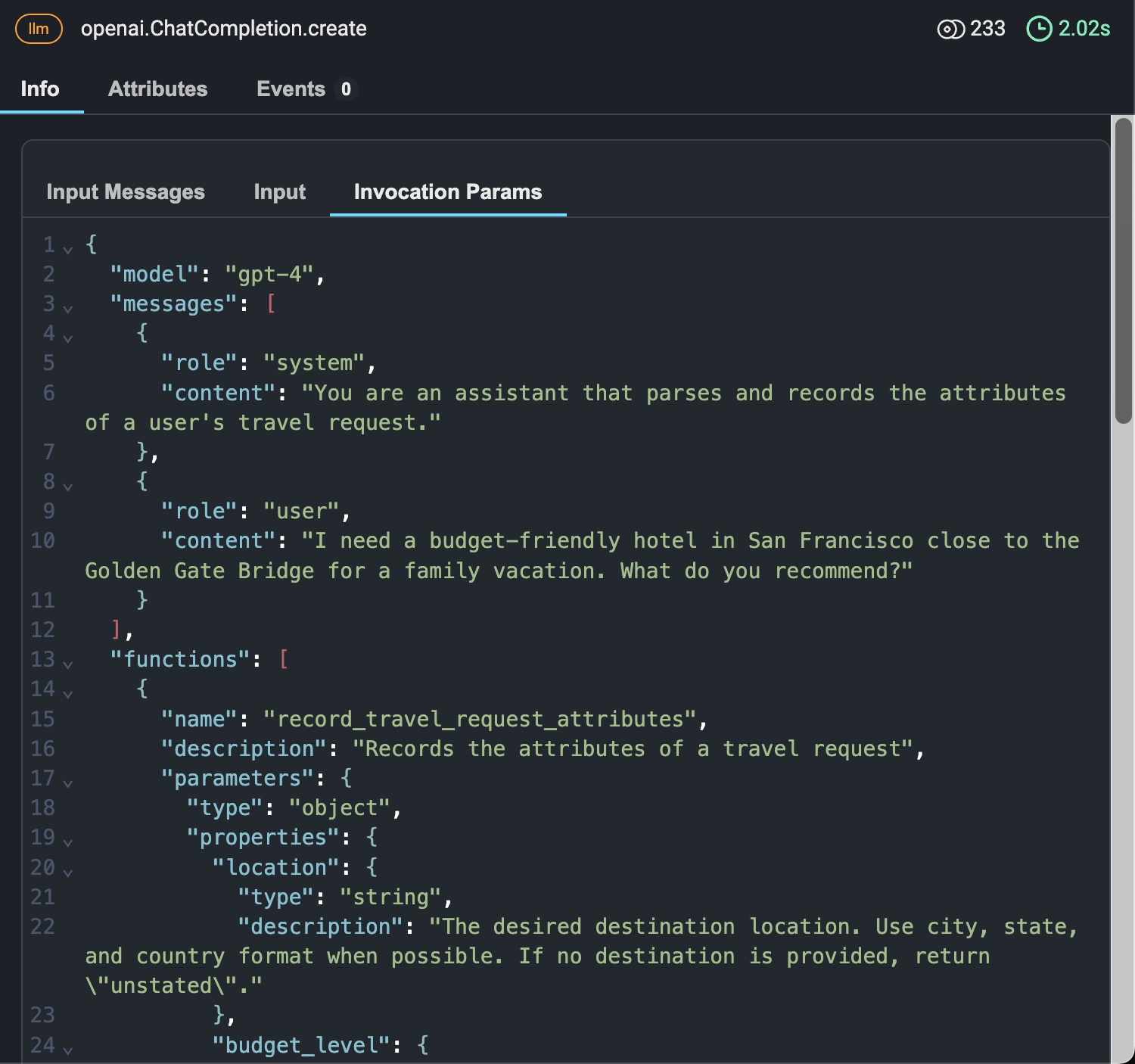
Verifying an individual trace invocation parameters
Evaluating the Extraction Performance
Point level evaluation is a great starting point, but verifying correctness of extraction at scale or in a batch pipeline can be challenging and expensive. Evaluating data extraction tasks performed by LLMs is inherently challenging due to factors like:- The diverse nature and format of source data.
- The potential absence of a ‘ground truth’ for comparison.
- The intricacies of context and meaning in extracted data.