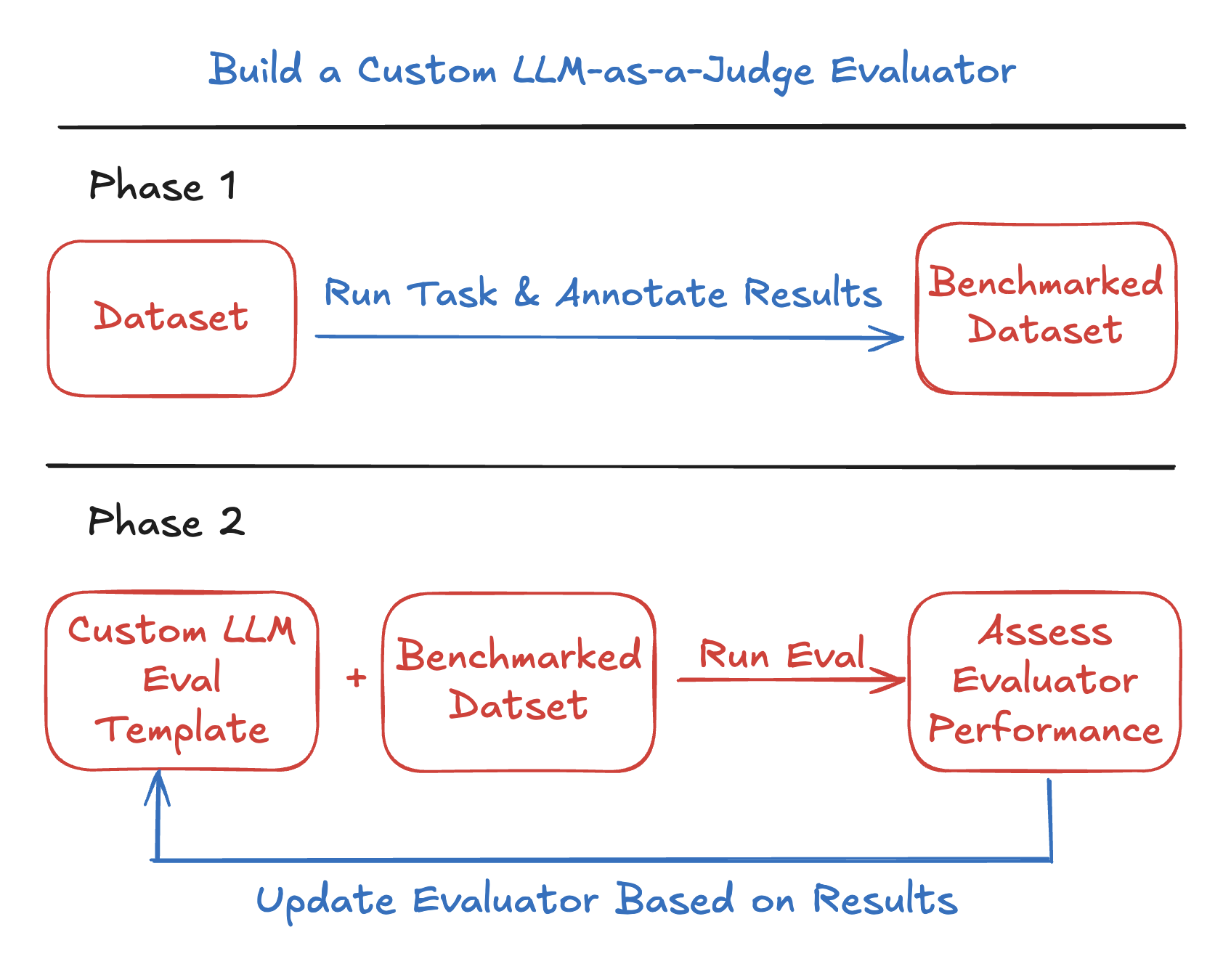
Creating a Custom LLM Evaluator with a Benchmark Dataset
Notebook Walkthrough
We will go through key code snippets on this page. To follow the full tutorial, check out the notebook or video above.
Google Colab
colab.research.google.com
Generate Image Classification Traces
In this tutorial, we’ll ask an LLM to generate expense reports from receipt images provided as public URLs. Running the cells below will generate traces, which you can explore directly in Phoenix for annotation. We’ll use GPT-4.1, which supports image inputs.Dataset Information: Jakob (2024). Receipt or Invoice Dataset. Roboflow Universe. CC BY 4.0. Available at: https://universe.roboflow.com/jakob-awn1e/receipt-or-invoice (accessed on 2025‑07‑29)
Create Benchmark Dataset
After generating traces, open Phoenix to begin annotating your dataset. In this example, we’ll annotate based on “accuracy”, but you can choose any evaluation criterion that fits your use case. Just be sure to update the query below to match the annotation key you’re using—this ensures the annotated examples are included in your benchmark dataset.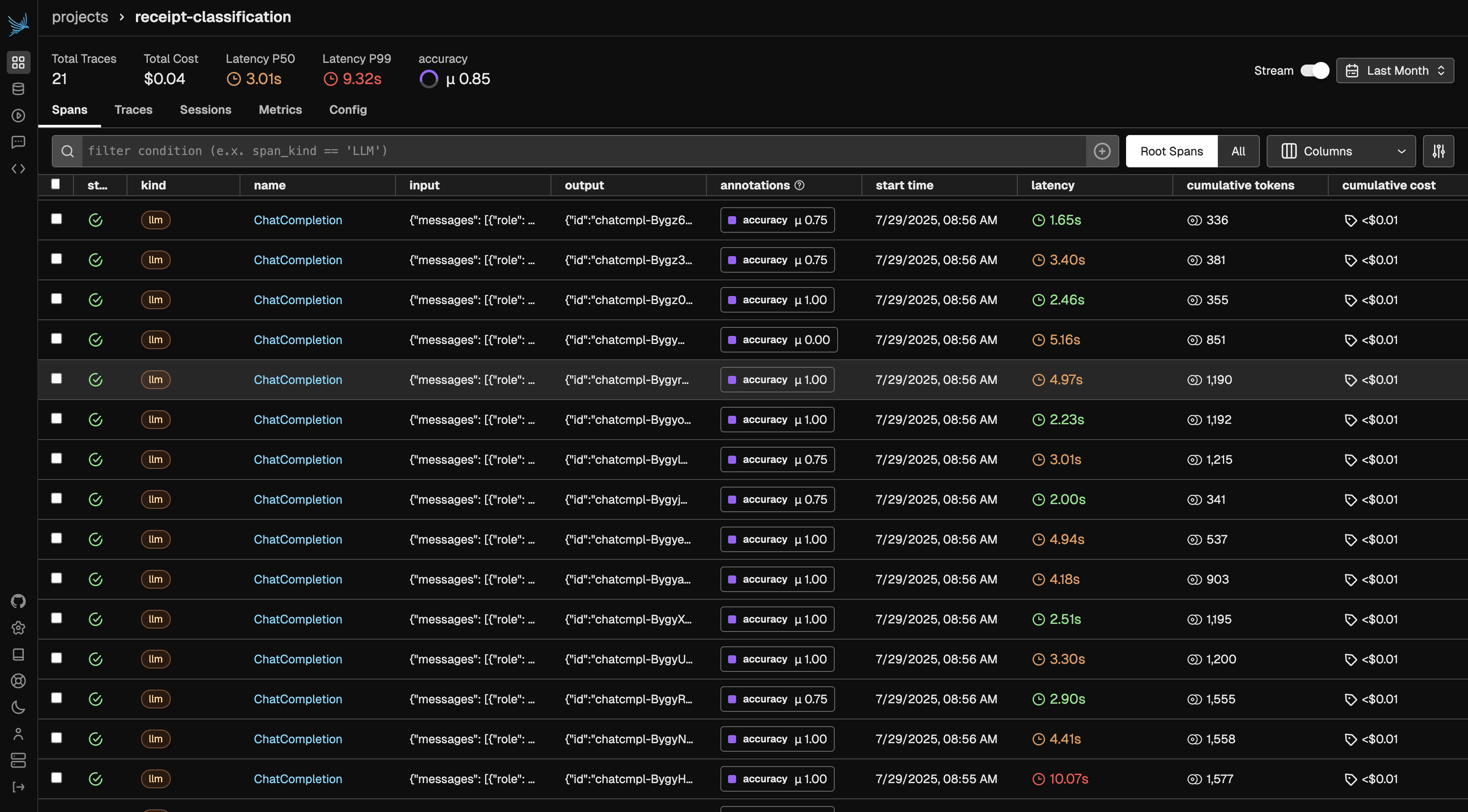
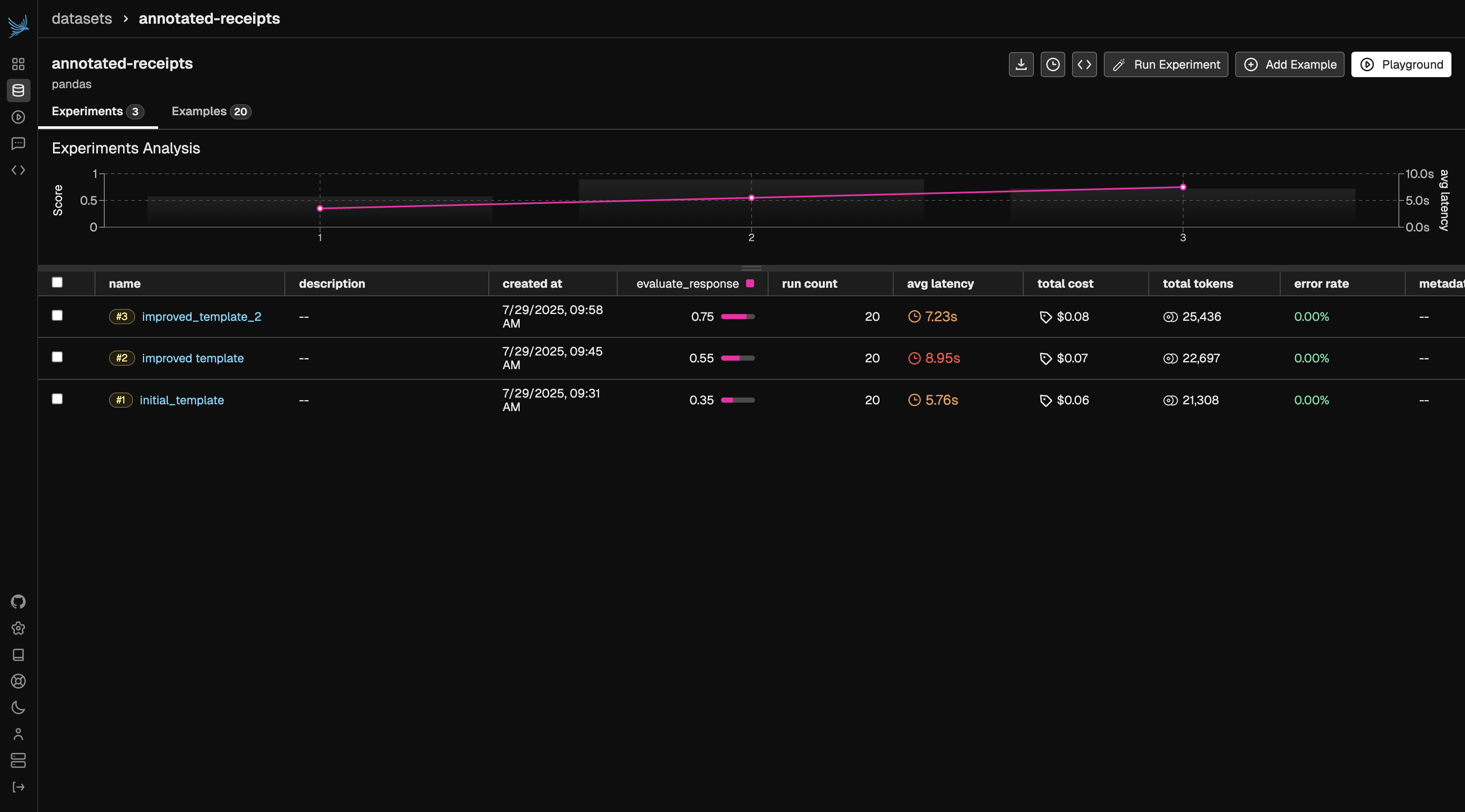
Create Evaluation Template & Run Experiment
Next, we’ll create a baseline evaluation template and define both the task and the evaluation function. Once these are set up, we’ll run an experiment to compare the evaluator’s performance against our ground truth annotations. In this case, our task function is llm_classify and our evaluator is a comparison between the task output and our annotated labels.Iterate on Prompt Template
Next, we’ll refine our evaluation prompt template by adding more specific instructions to classification rules. We can add these rules based on gaps we saw in the previous iteration. This additional guidance helps improve accuracy and ensures the evaluator’s judgments better align with human expectations.Results
Once your evaluator reaches a performance level you’re satisfied with, it’s ready for use. The target score will depend on your benchmark dataset and specific use case. You can define different thresholds and metrics you hope the evaluator to achieve. That said, you can continue applying the techniques from this tutorial to refine and iterate until the evaluator meets your desired level of quality.