Task Description
Coding Agents and Rule Files
Coding agents are a focal point of agent development today. They are often described as the industry’s most powerful agents, using state of the art LLMs, descriptive and effective tools, and carefully crafted architectures. Coding agents like Claude Code, Cursor, Cline, etc. tend to use one large system prompt for the entire application. Since this prompt plays a huge role in the execution of the agent, rule files are offered - where the user can write down a custom set of instructions to be appended to the system prompt. Developers spend time thinking about writing good rules so their coding agents can perform better. In this cookbook, we use Prompt Learning, an optimization technique, to optimize a user’s coding agent rules automatically. We use Prompt Learning to generate rulesets that lead to better accuracy for the user’s coding agent on their tasks.What is Prompt Learning?
Prompt Learning is an algorithm developed by Arize to optimize prompts based on data. See our detailed blog on Prompt Learning, and/or a quick summary of the algorithm below.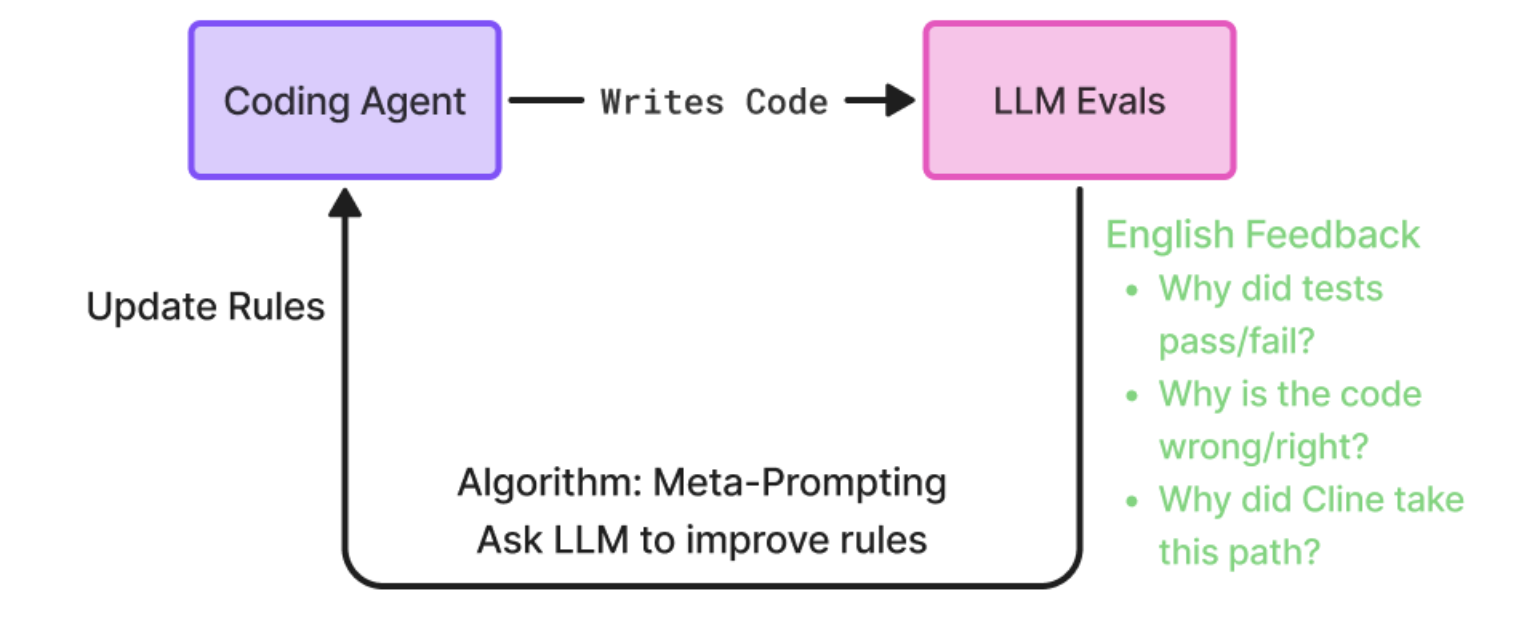
- Build dataset of inputs/queries
- Generate outputs with your unoptimized, base prompt
- Build LLM evals or human annotations to return natural language feedback
- e.g. explanations -> why this output was correct/incorrect (most powerful)
- e.g. confusion reason -> why the model may have been confused
- e.g. improvement suggestions -> where the prompt should be improved based on this input/output pair
- Use meta-prompting to optimize the original prompt
- feed prompt + inputs + outputs + evals + annotations to another LLM
- ask it to generate an optimized prompt!
- Run and evaluate new, optimized prompt with another experiment
Cline - Coding Agent
We chose to optimize Cline - a powerful, open source coding agent. We chose Cline because its open source - which allowed us to run benchmarks like SWE Bench (see below) much more easily! Cline exposes its rules through ./clinerules, in every project. Specifically, we’ll be running Cline in Act Mode - where Cline actually edits the codebase and generates patches. It will have full permissions to read, edit, delete, or generate any files. More about Cline ./clinerulesBenchmark - SWE Bench
We need a way to test the rules we are generating/optimizing. For this, we use widely known benchmark SWE Bench Lite - a set of 300 real issue pull requests from famous Python repositories, like Scikit-learn or Sympy.Phoenix - Experiment Tracking
We use Phoenix’s Experiments feature to track our Cline runs. Every time we run Cline with a ruleset, we can log that experiment to Phoenix, and track improvements over time.Setup
Prompt Learning Repository + Cline Cookbook
To view and run this cookbook, first clone the Prompt Learning repository.cline -> act_mode -> optimize_cline_act_PX.ipynb
You can see the notebook here. But keep in mind you will have to clone the repository and run the notebook within the cline folder for the notebook to run!
Cline + SWE Bench Setup
Make sure to go throughcline -> README.md. This walks you through how to set up Cline and SWE Bench.
Configuration
Configure the optimization with the following parameters:LOOPS: How many Prompt Learning loops - how many times you want to optimize Cline’s rules. We will be starting a blank, empty ruleset. So loop #1 generates a set of rules from scratch, and all loops afterwards will be optimizing the last loop’s ruleset.
TRAIN_SIZE: Size of training set. SWE Bench Lite has 300 datapoints. Here you can select how many of those datapoints you want to use to train the Prompt Learning optimizer on.
TEST_SIZE: Size of test set. Here you can select how many SWE Bench Lite datapoints you want to test each Cline ruleset with.
WORKERS: Concurrency. SWE-bench with Cline is set up to run in parallel, with however many workers you specify. 50 workers means each training/test set runs 50 examples at a time.
An individual Cline run can make anywhere from 5-25 LLM calls, making it an expensive task. Running Cline in parallel can also trigger rate limiting, depending on your plan with the LLM provider.Select your TRAIN_SIZE, TEST_SIZE, and WORKERS accordingly.
We recommend a 50/50 split here. A healthy balance between enough training data for Prompt Learning to succeed, but also enough test data for new rules to be properly evaluated, is required. Too much training data -> overfitting, too much test data - unreliable test accuracies.
Train/Test Datasets
Let’s load SWE Bench Lite, split it into train/test datasets, and then upload our training set to Phoenix.Helper: Log Experiments to Phoenix
This helper function logs experiment results to Phoenix, allowing us to visualize and track optimization progress across iterations.Optimization
cline folder. You can see the Code Appendix on this page as well.
In each loop, we
- Call
run_actto run Cline in Act Mode on the training set + test set. This function- Runs Cline on your chosen train/test subset of SWE Bench in parallel based on
WORKERS - Runs unit tests for each row, using
run_evaluationin the SWE Bench package, computing accuracy (how many problems did Cline accurately solve) - Returns Cline’s patches (git diff) for every row, along with pass/fail
- Runs Cline on your chosen train/test subset of SWE Bench in parallel based on
- Call
evaluate_resultson the training set to generate LLM Evals. We ask an LLM to evaluate the patch from Cline, telling us why its wrong/right, and why Cline may have made those changes. - Call
log_experiment_with_idsto log this training run to Phoenix. This helps us view each iteration on a graph, so we can track if our ruleset optimizations are making Cline improve. - Initialize
PromptLearningOptimizerand calloptimize, which generates a new ruleset based on the training data we collected, and the old ruleset. - Saves training accuracy, test accuracy, and optimized ruleset to
act_rulesetsfolder.
Results
Visit the Datasets and Experiments tab in Phoenix and view your experiment results. Here’s an example of one run, where we just ran 2 loops and saw a huge boost in training accuracy.
act_rulesets folder.
Code Appendix
A lot of the code in this notebook is abstracted into helper functions.cline -> CODE_APPENDIX.md covers what some of the most important helper functions do.