Annotation Types
Depending on what you want to do with your annotations, you may want to configure a rubric for what your annotation represents - e.g. is it a category, number with a range (continuous), or freeform.- Annotation type:
- Categorical: Predefined labels for selection. (e.x. 👍 or 👎)\
- Continuous: a score across a specified range. (e.g. confidence score 0-100)\
- Freeform: Open-ended text comments. (e.g. “correct”)
- Optimize the direction based on your goal:
- Maximize: higher scores are better. (e.g. confidence)\
- Minimize: lower scores are better. (e.g. hallucinations)\
- None: direction optimization does not apply. (e.g. tone)

Different types of annotations change the way human annotators provide feedback
Annotation Targets
Phoenix supports annotating different annotation targets to capture different levels of LLM application performance. The core annotation types include:- Span Annotations: Applied to individual spans within a trace, providing granular feedback about specific components
- Document Annotations: Specifically for retrieval systems, evaluating individual documents with metrics like relevance and precision
- Labels: Text-based classifications (e.g., “helpful” or “not helpful”)
- Scores: Numeric evaluations (e.g., 0-1 scale for relevance)
- Explanations: Detailed justifications for the annotation
- Human feedback (e.g., thumbs up/down from end-users)
- LLM-as-a-judge evaluations (automated assessments)
- Code-based evaluations (programmatic metrics)
Feedback from End-users
Human feedback allows you to understand how your users are experiencing your application and helps draw attention to problematic traces. Phoenix makes it easy to collect feedback for traces and view it in the context of the trace, as well as filter all your traces based on the feedback annotations you send. Before anything else, you want to know if your users or customers are happy with your product. This can be as straightforward as adding :thumbsup: :thumbsdown: buttons to your application, and logging the result as annotations. For more information on how to wire up your application to collect feedback from your users, see here.Evaluations from LLMs
When you have large amounts of data it can be immensely efficient and valuable to leverage LLM judges viaevals to produce labels and scores to annotate your traces with. Phoenix’s evals library as well as other third-party eval libraries can be leveraged to annotate your spans with evaluations. For details see Running Evals on Traces to:
- Generate evaluation results
- Add evaluation results to spans
Human Annotations
Sometimes you need to rely on human annotators to attach feedback to specific traces of your application. Human annotations through the UI can be thought of as manual quality assurance. While it can be a bit more labor intensive, it can help in sharing insights within a team, curating datasets of good/bad examples, and even in training an LLM judge.How to Use Annotations
Annotations can help you share valuable insight about how your application is performing. However making these insights actionable can be difficult. With Phoenix, the annotations you add to your trace data is propagated to datasets so that you can use the annotations during experimentation.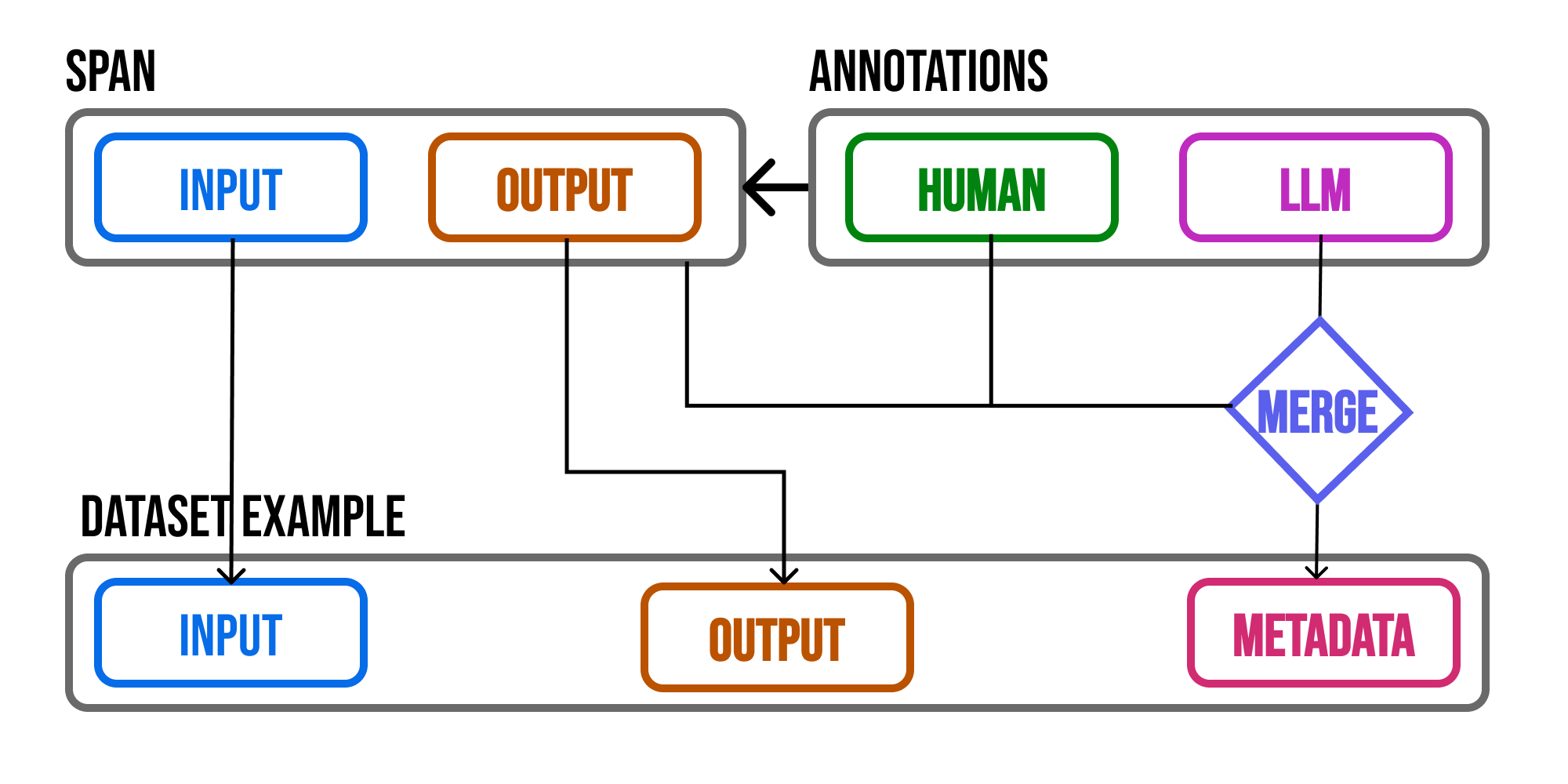
A span's attributes as well as annotations are propagated to example metadata
Track Improvements during Experimentation
Since Phoenix datasets preserve the annotations, you can track whether or not changes to your application (e.g. experimentation) produce better results (e.g. better scores / labels). Phoenix evaluators have access to the example metadata at evaluation time, making it possible to track improvements / regressions over previous generations (e.g. the previous annotations).Train an LLM Judge
AI development currently faces challenges when evaluating LLM application outputs at scale:- Human annotation is precise but time-consuming and impossible to scale efficiently.
- Existing automated methods using LLM judges require careful prompt engineering and often fall short of capturing human evaluation nuances.
- Solutions requiring extensive human resources are difficult to scale and manage.
Annotator Kind
Phoenix supports three types of annotators: Human, LLM, and Code.| Annotator Kind | Source | Purpose | Strengths | Use Case |
|---|---|---|---|---|
| Human | Manual review | Expert judgment and quality assurance | High accuracy, nuanced understanding | Manual QA, edge cases, subjective evaluation |
| LLM | Language model output | Scalable evaluation of application responses | Fast, scalable, consistent across examples | Large-scale output scoring, pattern review |
| Code | Programmatic evaluators | Automated assessment based on rules/metrics | Objective, repeatable, useful in experiments | Model benchmarking, regression testing |