boto3 provides Python bindings to AWS services, including Bedrock, which provides access to a number of foundation models. Calls to these models can be instrumented using OpenInference, enabling OpenTelemetry-compliant observability of applications built using these models. Traces collected using OpenInference can be viewed in Phoenix.
OpenInference Traces collect telemetry data about the execution of your LLM application. Consider using this instrumentation to understand how a Bedrock-managed models are being called inside a complex system and to troubleshoot issues such as extraction and response synthesis.
Launch Phoenix
Phoenix Cloud
Command Line
Docker
Notebook
Sign up for Phoenix:
-
Sign up for an Arize Phoenix account at https://app.phoenix.arize.com/login
-
Click
Create Space, then follow the prompts to create and launch your space.
Install packages:pip install arize-phoenix-otel
-
Create your API key from the Settings page
-
Copy your
Hostname from the Settings page
-
In your code, set your endpoint and API key:
import os
os.environ["PHOENIX_API_KEY"] = "ADD YOUR PHOENIX API KEY"
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "ADD YOUR PHOENIX HOSTNAME"
# If you created your Phoenix Cloud instance before June 24th, 2025,
# you also need to set the API key as a header:
# os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={os.getenv('PHOENIX_API_KEY')}"
Install
pip install openinference-instrumentation-bedrock opentelemetry-exporter-otlp
Setup
Connect to your Phoenix instance using the register function.
from phoenix.otel import register
# configure the Phoenix tracer
tracer_provider = register(
project_name="my-llm-app", # Default is 'default'
auto_instrument=True # Auto-instrument your app based on installed OI dependencies
)
boto3 prior to initializing a bedrock-runtime client. All clients created after instrumentation will send traces on all calls to invoke_model.
import boto3
session = boto3.session.Session()
client = session.client("bedrock-runtime")
Run Bedrock
From here you can run Bedrock as normal
prompt = (
b'{"prompt": "Human: Hello there, how are you? Assistant:", "max_tokens_to_sample": 1024}'
)
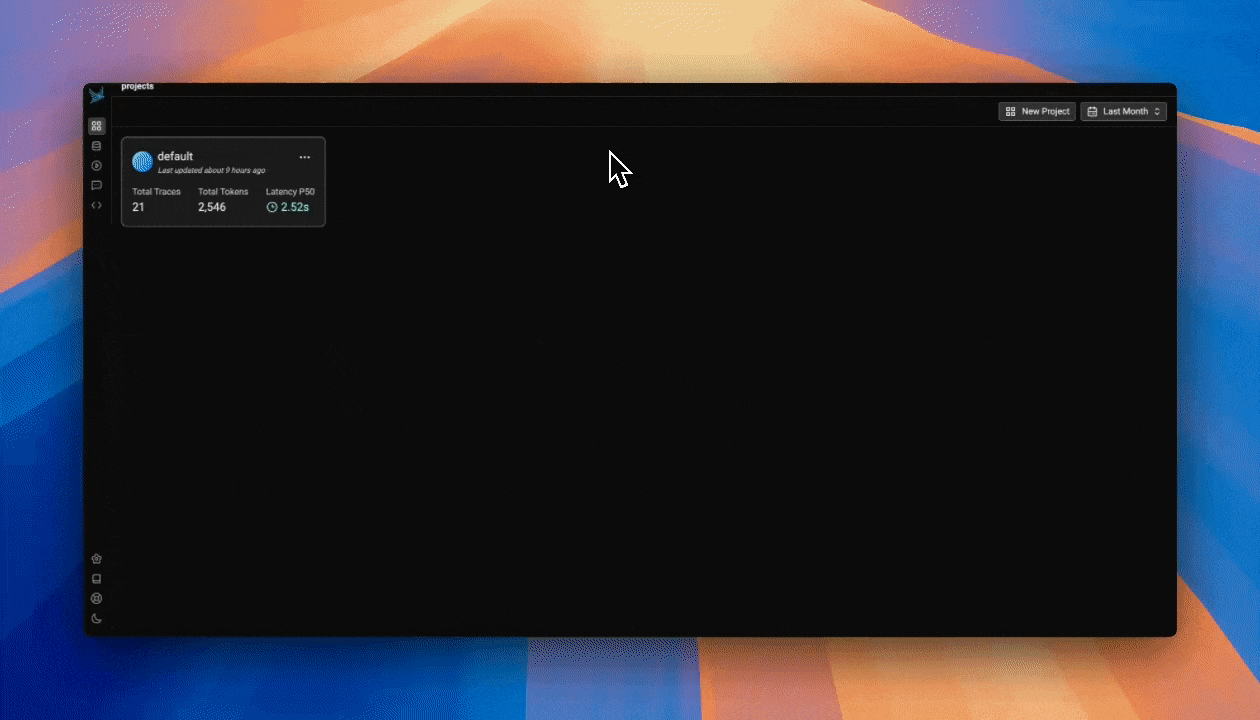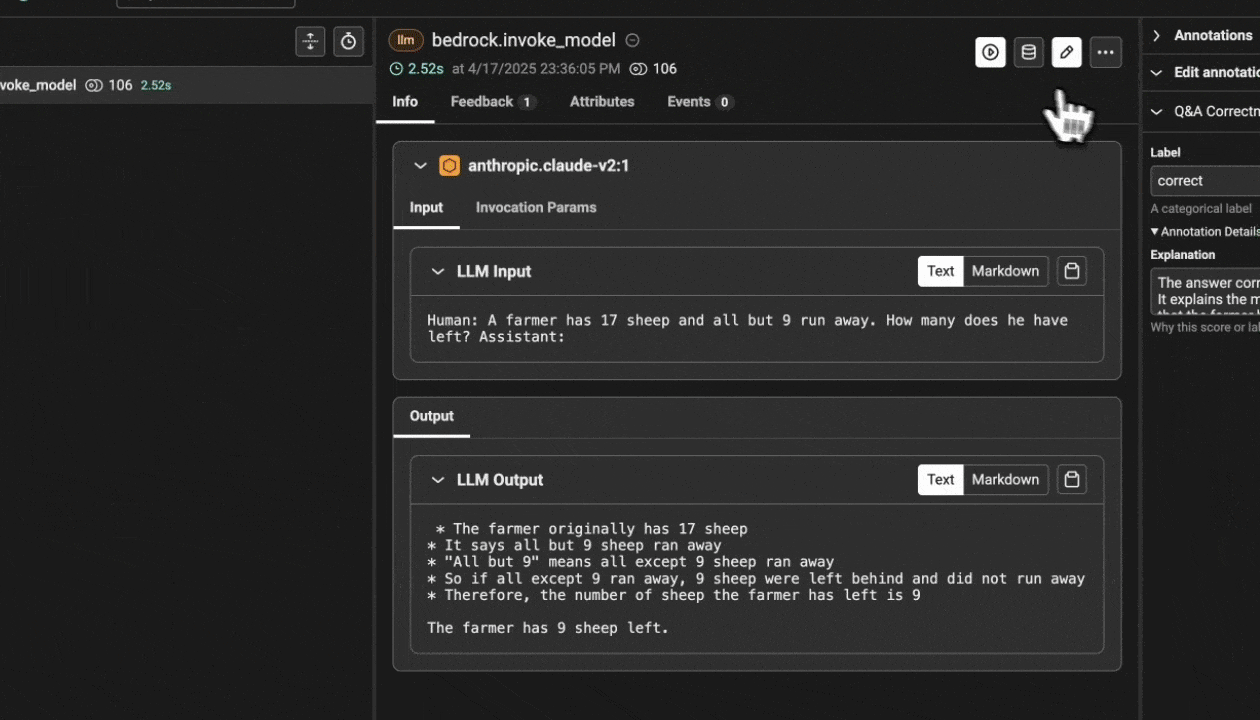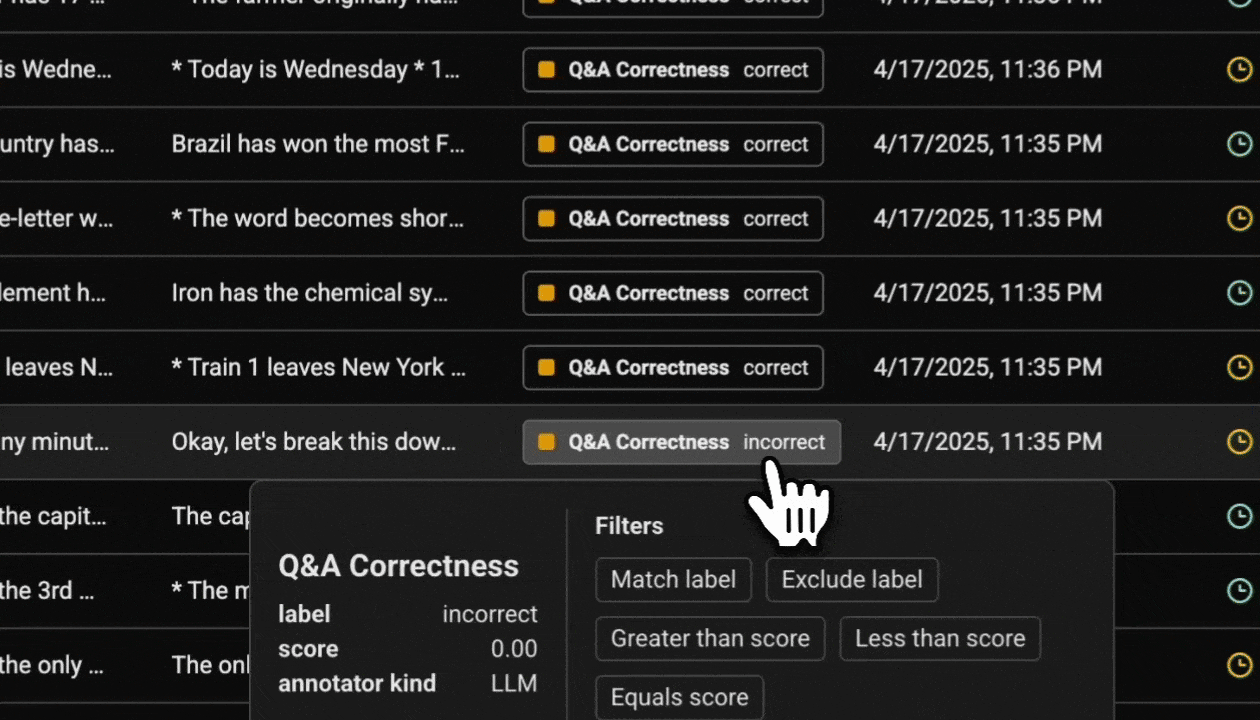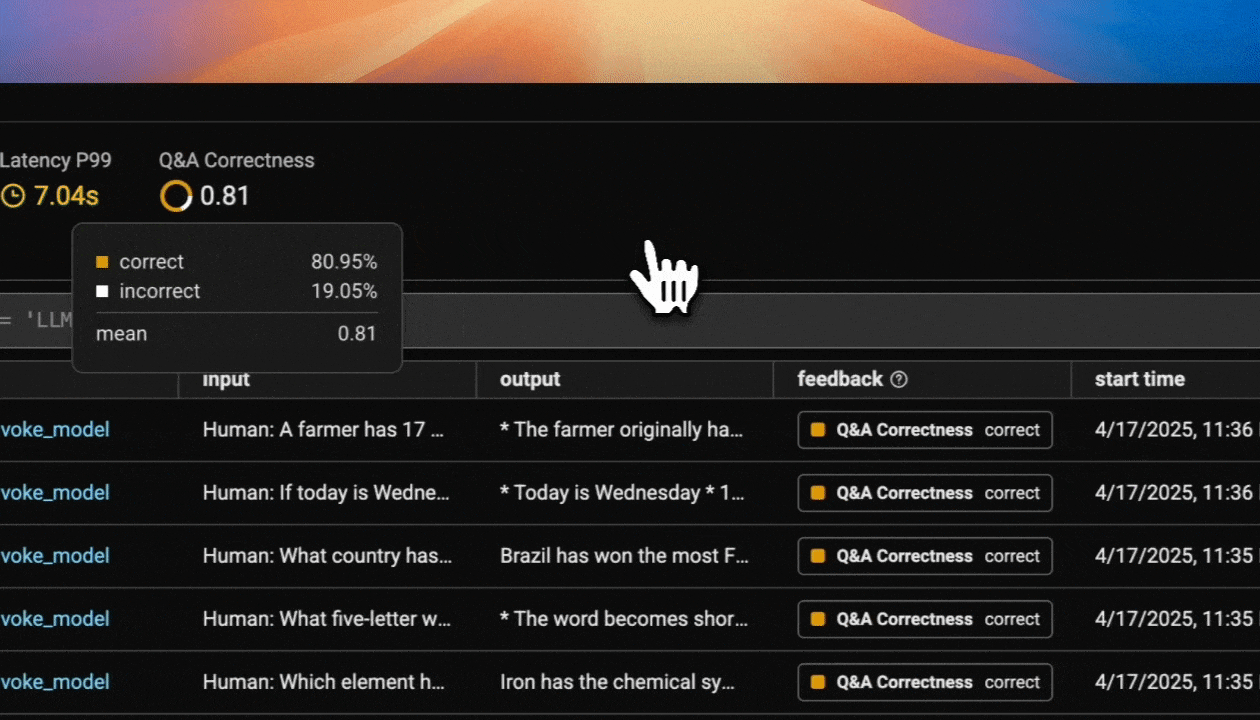
response = client.invoke_model(modelId="anthropic.claude-v2", body=prompt)
response_body = json.loads(response.get("body").read())
print(response_body["completion"])
Warning: Use converse instead of invoke_model for Meta models on Amazon Bedrock.Outputs from Meta models (such as Llama 3) are not currently traced when using the invoke_model API.This issue is known, and a fix is actively in progress.
Observe
Now that you have tracing setup, all calls to invoke_model will be streamed to your running Phoenix for observability and evaluation.
Resources