From CSV
When manually creating a dataset (let’s say collecting hypothetical questions and answers), the easiest way to start is by using a spreadsheet. Once you’ve collected the information, you can simply upload the CSV of your data to the Phoenix platform using the UI. You can also programmatically upload tabular data using Pandas as seen below.From Pandas
- Python
From Objects
Sometimes you just want to upload datasets using plain objects as CSVs and DataFrames can be too restrictive about the keys.- Python
Synthetic Data
One of the quickest ways of getting started is to produce synthetic queries using an LLM.- Python
One use case for synthetic data creation is when you want to test your RAG pipeline. You can leverage an LLM to synthesize hypothetical questions about your knowledge base.In the below example we will use Phoenix’s built-in Imagine you have a knowledge-base that contains the following documents:Once your synthetic data has been created, this data can be uploaded to Phoenix for later re-use.Once we’ve constructed a collection of synthetic questions, we can upload them to a Phoenix dataset.
llm_generate, but you can leverage any synthetic dataset creation tool you’d like.Before running this example, ensure you’ve set your
OPENAI_API_KEY environment variable.From Spans
If you have an application that is traced using instrumentation, you can quickly add any span or group of spans using the Phoenix UI. To add a single span to a dataset, simply select the span in the trace details view. You should see an add to dataset button on the top right. From there you can select the dataset you would like to add it to and make any changes you might need to make before saving the example.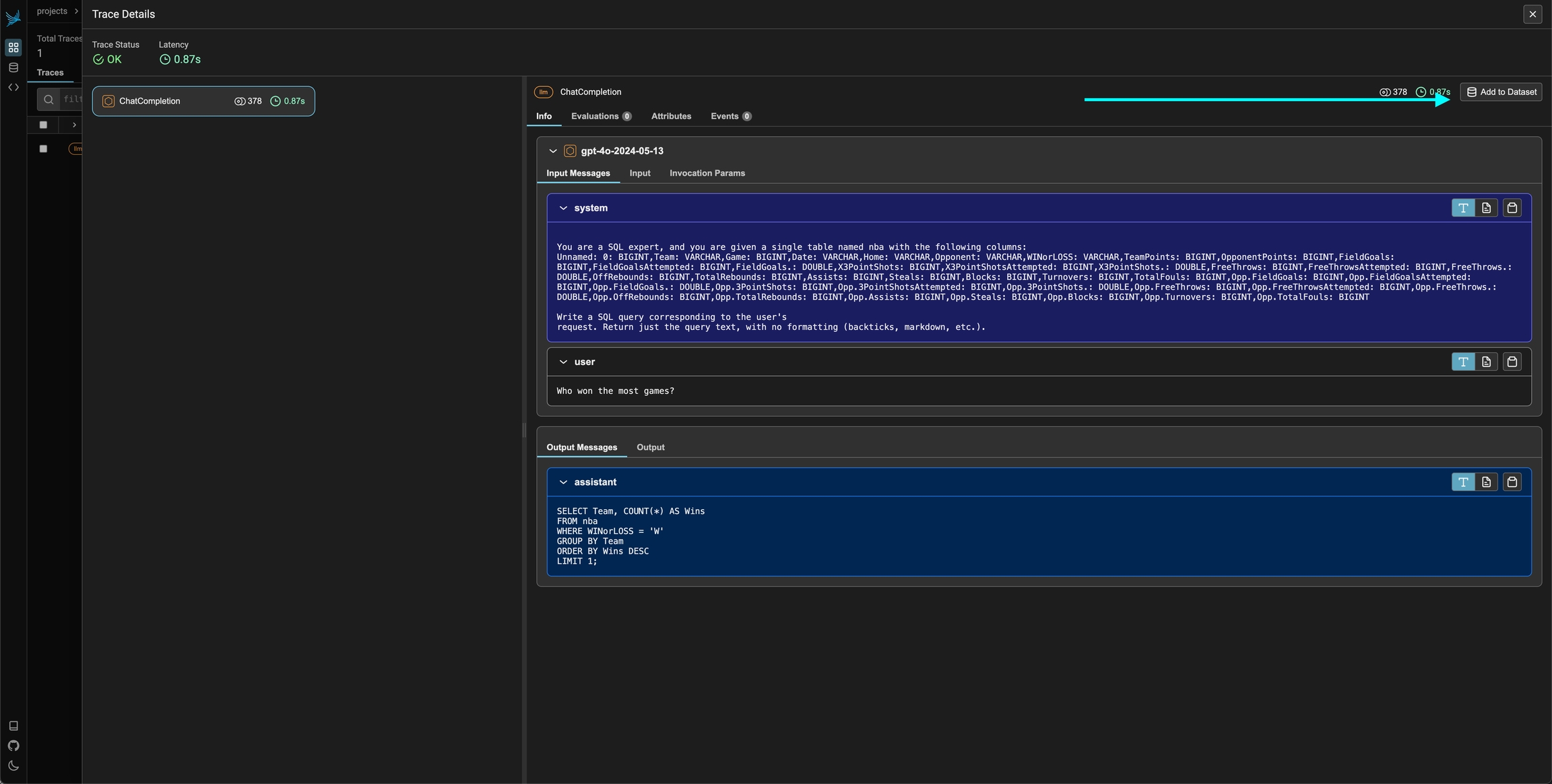
Add a specific span as a golden dataset or an example for further testing
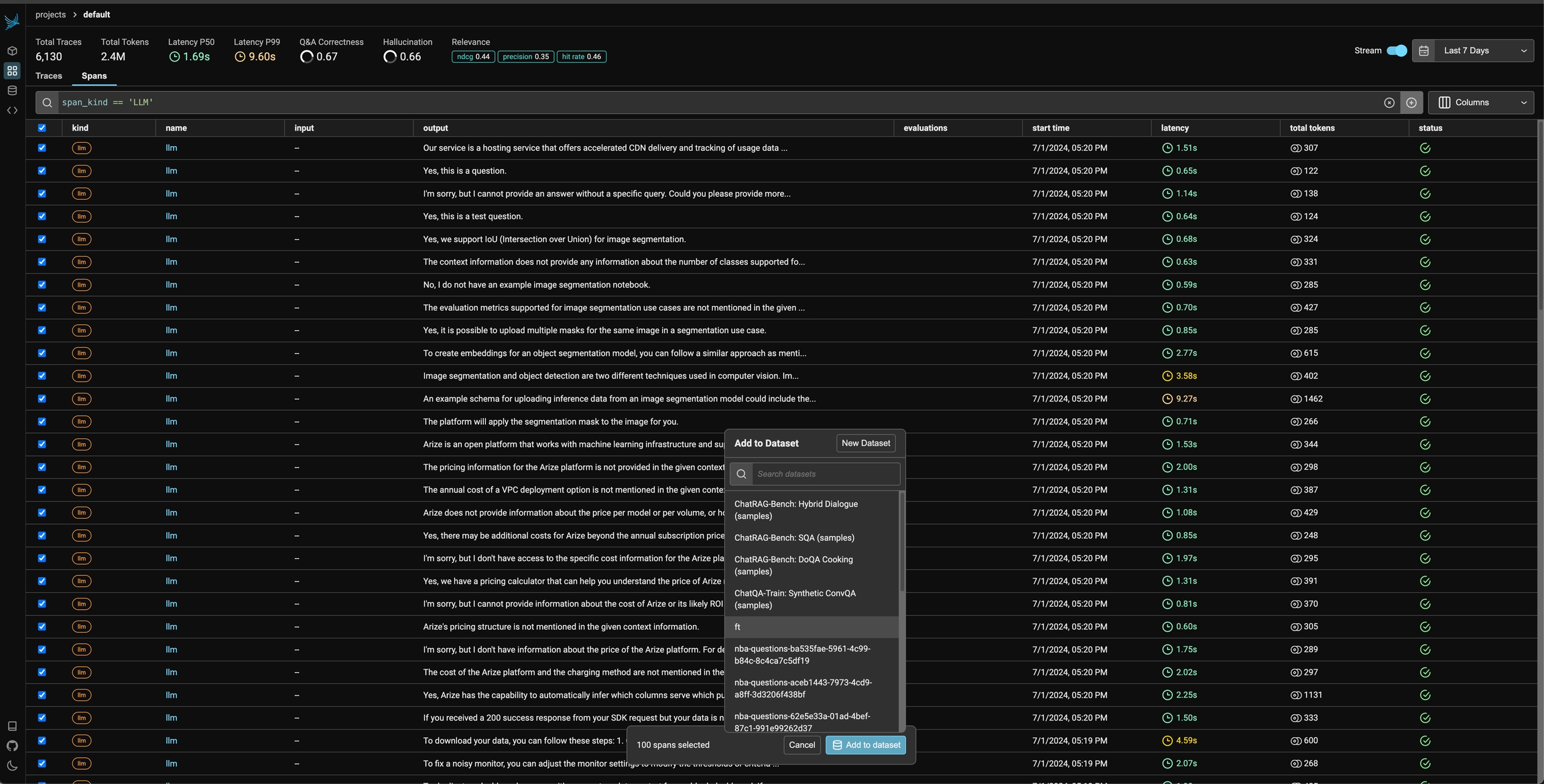
Add LLM spans for fine tuning to a dataset